ユーザー任意のソートとLexoRankについて
よくある組織階層を作りたい
システムの開発でこういう組織図のようなツリー構造を作りたい場面ってよくありますよね。各階層の中の要素は、ユーザーが任意の順番で並び替えたいとします。社長が新入社員よりも下に表示されていたら怒られますからね。
会社
├── 営業部
│ ├── 営業企画課 ↓任意の順番で並び替えられる
│ └── 営業推進課 ↑
├── 企画部
│ ├── 商品企画課
│ └── 市場分析課
├── 技術部
│ ├── 開発課
│ └── 品質管理課
└── 総務部
├── 人事課
├── 経理課
└── 広報課
このとき、単純にこのようなデータ構造を考えるかもしれません。
[
{ "id": 1, "name": "営業部", "parent": 1, "sort_order": 1 },
{ "id": 2, "name": "企画部", "parent": 1, "sort_order": 2 },
{ "id": 3, "name": "技術部", "parent": 1, "sort_order": 3 }
]これだと例えば総務部の配下にある全部署の社員を取得したいとか、直属の部署をすべて取得したいときにクエリが増えるので大変ですねという話を前に書きました。そういうときは入れ子集合モデルが有効な選択肢になります。
今回は階層の話ではなく、任意順のソートの話です
上のようにsort_orderカラムでソート順を表現する場合、表示順を変更するたびに、同じ階層のすべてのレコードのsort_orderを変更しなければなりません。並び順をごにょごにょと変更してから、一括保存するUIだと自ずとそうなりますね。
保存するたびにUPDATE文を複数回発行するのは嫌なので、一度で済ましたいと思うかもしれません。MySQLだと、ELT()とFIELD()を使ってバルクアップデートのようなことができます。
// sort_orderをID 2,4,5の順に更新
UPDATE `departments` SET
sort_order = ELT(FIELD(id,2,4,5),1,2,3)
WHERE id IN (2,4,5)保存対象となるレコードが多ければ、それだけSQLが長くなり、最悪クエリサイズの上限に引っかかることがあるので注意が必要です。数千件くらいまでなら問題なく使えるようです。じゃあそれ以上ならどうなるんだとなるわけですが、この方法だと、そもそも並び替えできるレコードの上限がUIに依存している(何万件も同じページに表示して操作するのは現実的なUIではない)ので、せいぜい1000件くらいまでの並び替えを想定したデータ構造と考えるのが良さそうです。
毎回多くのレコードを更新するのは嫌だ
とはいえ、並び順を更新する頻度が高い場合には、保存するたびに1000件分のレコードのUPDATEが実行されてしまうわけで、もっと効率よくしたいと考えるのも当然でしょう。
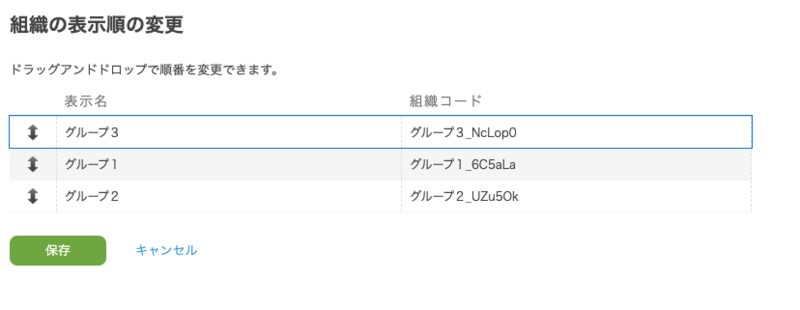
しかも、最近のUIはいちいち保存ボタンを押さなくても、ドラッグ・アンド・ドロップで並び替えたタイミングで保存されるのが一般的です。Runbookのフォルダーの表示順の並び替えも、移動が確定したタイミングで保存されるようになっています。
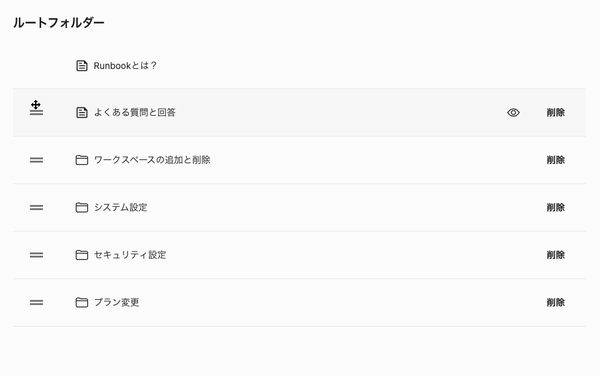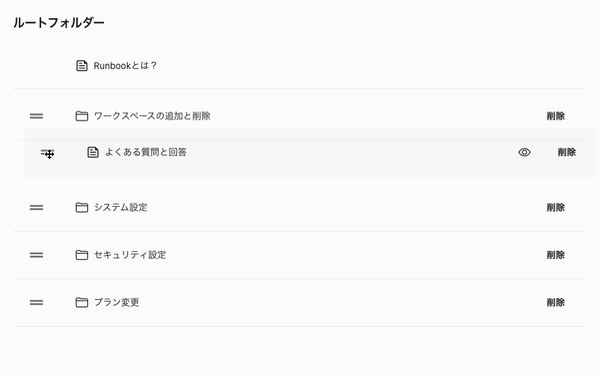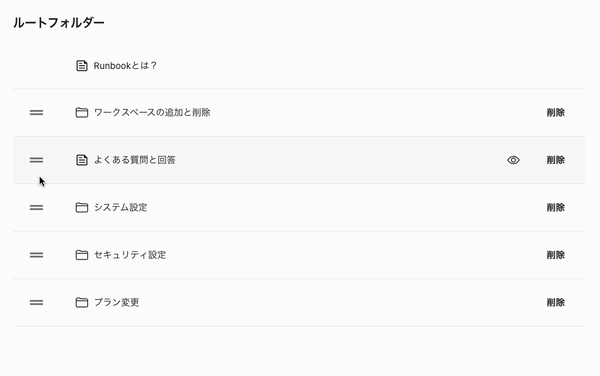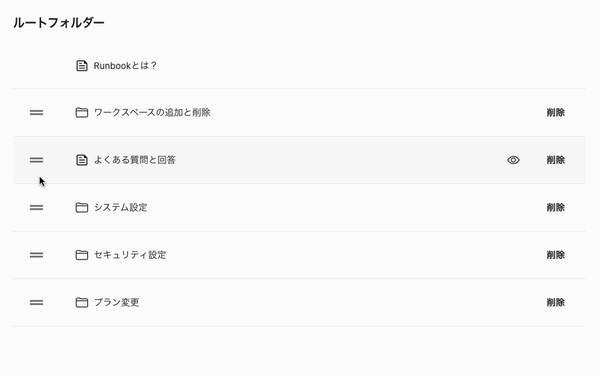
sort_orderを一括更新する方法で、このようなUIを実現しようとすると、確定したタイミングで同じ階層の複数のレコードを更新しないといけませんから、より効率が悪くなります。これを解決する方法はいくつかあって、代表的なのは、sort_orderを間隔を空けて持つ、または浮動小数点数で持つ方法があります。
間隔を空けて持つ場合
[
{ "id": 1, "name": "営業部", "parent": 1, "sort_order": 100 },
{ "id": 2, "name": "企画部", "parent": 1, "sort_order": 200 },
{ "id": 3, "name": "技術部", "parent": 1, "sort_order": 300 }
]浮動小数点数で持つ場合
[
{ "id": 1, "name": "営業部", "parent": 1, "sort_order": 1.0 },
{ "id": 2, "name": "企画部", "parent": 1, "sort_order": 1.5 },
{ "id": 3, "name": "技術部", "parent": 1, "sort_order": 2.0 }
]いずれの方法も、ある要素を別の位置に移動する際には、そのレコードのsort_orderを変更するだけで済みます。id:3の要素をid:2の位置に移動する場合、間隔を空けて持つ場合のsort_orderの値は150、浮動小数点数で持つ場合は1.25となります。注意点としては、どちらも並び替えを繰り返していると、いずれは限界(前者は前後の差が1になる、後者はdoubleで表せられる限界)が来てしまうので、値を割り当て直さないといけなくなることです。
間隔を空けて持つ場合のリバランス
1. 総務部を営業部の下に入れたいが隙間がない
[
{ "id": 1, "name": "営業部", "parent": 1, "sort_order": 100 },
{ "id": 2, "name": "企画部", "parent": 1, "sort_order": 101 },
{ "id": 3, "name": "総務部", "parent": 1, "sort_order": 200 },
{ "id": 4, "name": "技術部", "parent": 1, "sort_order": 300 }
]
2. 2番目以降のsort_orderに100×2を足す
[
{ "id": 1, "name": "営業部", "parent": 1, "sort_order": 100 },
{ "id": 2, "name": "企画部", "parent": 1, "sort_order": 301 },
{ "id": 3, "name": "総務部", "parent": 1, "sort_order": 400 },
{ "id": 4, "name": "技術部", "parent": 1, "sort_order": 500 }
]
3. 再度試行する
[
{ "id": 1, "name": "営業部", "parent": 1, "sort_order": 100 },
{ "id": 3, "name": "総務部", "parent": 1, "sort_order": 200 },
{ "id": 2, "name": "企画部", "parent": 1, "sort_order": 301 },
{ "id": 4, "name": "技術部", "parent": 1, "sort_order": 500 }
]この例では間隔を100としているので、同じ位置に7回要素を挿入すると、値のリバランス(再割り当て)が発生してしまいます。間隔を大きくすればリバランスの頻度を減らすことができますが、その分大きな値を割り当てないといけなくなるので、オーバーフローする可能性があることを考慮しないといけません。
浮動小数点数で持つ場合のリバランス
浮動小数点数で持つ場合、doubleの仮数部は52ビットなので、40〜50回程度まではリバランスなしに挿入することができます(回数は値の大きさによる)。ただし、リバランスが発生したときには、整数のようにそれ以上のレコードに1を足すみたいなことはできない(浮動小数点数の演算には指数部をそろえないといけないので、値が丸められる可能性がある)ので、全レコードに対して整数値などにリバランスすることになります。従って1クエリではリバランスできませんし、リバランスの際はトランザクションにより一貫性を保たなければならないのでパフォーマンスの観点から懸念が生じます。
LexoRankについて
LexoRankはJiraで採用されているランキングのアルゴリズムです。
LexoRankのアルゴリズムの説明はこのサイトがめちゃくちゃ分かりやすいので、そちらを参照してください。
LexoRankはsort_orderを数値ではなく以下のような形式の文字列で表します。
バケット|値の文字列例えば、以下のような文字列になります。
0|hzzzzz
0|i00000このふたつのレコードの間に値を入れるには、可変長の文字列を増やします。
0|hzzzzz
0|hzzzzzi ←追加した
0|i00000つまり、原理的には数値か文字列かの違いだけで、浮動小数点数を使う方法と同じなのですが、特徴は値の先頭にバケットという特別な符号がついていることです。このバケットは、リバランスのたびに、0、1、2と値が変化します。2の次はまた0になります。これの何がうれしいかというと、リバランスのときにトランザクションによる一貫性の保護を行わなくても、順序が保たれるという利点があります。
1. リバランス前
0|hzzzzz
0|hzzzzzi
0|i00000
2. 下からリバランスすれば順番が保たれる
0|hzzzzz
0|hzzzzzi
1|cccccc ←リバランス
0|hzzzzz
1|bbbbbb ←リバランス
1|cccccc
1|aaaaaa ←リバランス
1|bbbbbb
1|ccccccJiraが採用しているアルゴリズムということで、スマートでイケてる感じがしますね。
TypeScriptによる実装
で結局なにを使えばいいのか
実はRunbookでフォルダーの階層構造を実装するにあたって、最初はLexoRankを採用しようと思って仮で実装までしてみたのですが、レースコンディションでランクの値が重複してしまう問題があり、レコードの追加や移動のたびにロックを取るのも嫌だったので、結局採用は見送りました。またリバランスを逐次的に実行できるのはメリットではあるのですが、何も考えず実装すると、リバランスそのものが競合する可能性がありました。おそらくJiraでは大規模なランキングのしくみを実現するための専用のサービスが存在しており、競合が発生しないようにうまいことやっているのではないかと思います。Runbookではフォルダー内のコンテンツがせいぜい1000未満のオーダーであり、並び替えがそれほど頻繁に発生するわけではないので、間隔を空けて整数値でデータを持つことにしました。もちろんこの方法でもレースコンディションは発生するのですが、LexoRankと比べて影響が小さいと判断しました。
まとめ
ユーザー任意の順番での並べ替えで最適な方法は、どのようなUIを提供したいかや、並び替え対象のレコード数、パフォーマンス要件などによって変わります。
100件程度のレコードを並び替えてまとめて保存したい。
→階層内の全レコードをバルクアップデート
1000件程度のレコードをドラッグ・アンド・ドロップで並び替えたい。
→間隔を空けて対象のレコードのみアップデート。必要に応じてリバランスする。
さらに大量のレコードを並び替えたい。
→LexoRankでがんばる
うちはこんな方法でやってるよなどありましたら、@ryokdyまでお知らせください!